latent-transcription
Cross-modal variational inference for musical transcription and generation
This support page provides additional examples for the article Cross-modal variational inference for musical transcription and generation, submitted at DAFX2019. You can find the corresponding code here
Music transcription, that consists in extracting rel- evant musical annotations from an audio signal, is still an active field of research in the domain of Musical Information Retrieval. This complex task, that is also related to other topics such as pitch extraction or instrument recognition, is a demanding subject that gave birth to numerous approaches, mostly based on advanced signal processing-based algorithms. However, these techniques are often non-generic, allowing the extraction of definite physical properties of the signal (pitch, octave), but not allowing arbitrary vocabularies or more general annotations. On top of that, these techniques are one-sided, meaning that they can extract symbolic data from an audio signal, but cannot perform the reverse process and make symbol-to-signal generation. In this paper, we propose an alternative approach to music transcription by turning this problem into a density estimation task over signal and symbolic domains, considered both as related random variables. We estimate this joint distribution with two different variational auto-encoders, one for each domain, whose inner representations are forced to match with an additive constraint. This system allows both models to learn and generate separately, but also allows signal-to-symbol and symbol-to-signal inference, thus performing musical transcription and label-constrained audio generation. In addition to its versatility, this system is rather light during training and generation while allowing several interesting creative uses.
This support page provides the following elements:
- Reconstructions of instrumental sound distributions
- Symbol-to-signal inference
- Signal-to-symbol inference
- Sound morphing and free navigation
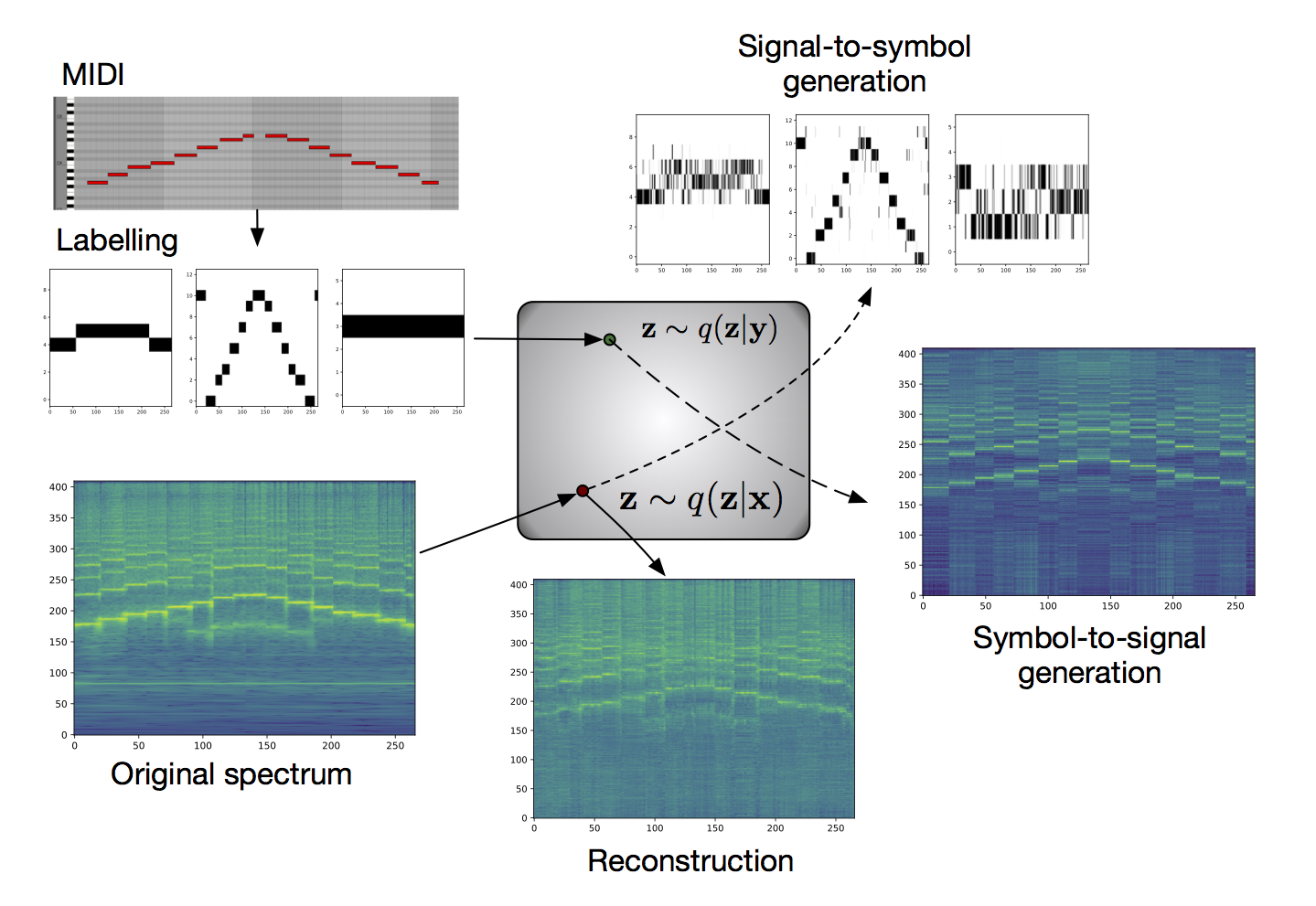
Reconstructions of instrumental sound distributions
Below we show some examples of reconstructions and transfer from random excerpts from the dataset. Once the NSGT is obtained, phase is reconstructed with a Griffin-Lim algorithm with about 30 iterations ; we thus also put the inversed original NSGT to have a good comparison basis.
Symbol-to-signal inference
Here we show examples of symbols to signal inference : taking a combination of labels [octave, pitch class, dynamics], we sample the corresponding latent distirbutions and pass it through the signal decoder (here, the midi file arpeg-FMaj-060BPM-leg-lined.mid of the Cantos & al. dataset)
- Flute
- Piano
- Trumpet-C
- Violin
Signal-to-symbol inference
Sound morphing
Here, we take an incoming sequence of labels and transfer it into the signal domain with 1) no latent interpolation 2) linear interpolation 3) cubic interpolation. We can hear that interpolating between latent positions gives more natural transitions, and show at which point the latent space is smooth and well-organized.
| No interpolation | Linear interpolation | Cubic interpolation | |
| Alto-Sax | |||
| Flute | |||
| Piano | |||
| Trumpet-C | |||
| Violin |
Free generation
Finally, we show some random trajectories that we directly invert with the signal auto-encoder (tribute to Tristan Murail…!)
| Alto-Sax | ||||
| Flute | ||||
| Piano | ||||
| Trumpet-C | ||||
| Violin |